Prism Release Preview 18th November 2015
- Results clustering
- ePrints integration – author search
- EDS Integration – Year Published facet
- EDS Integration – select and sort facets
- EDS Integration – fix hidden bib details for signed in users
- Lists moderation queue fix
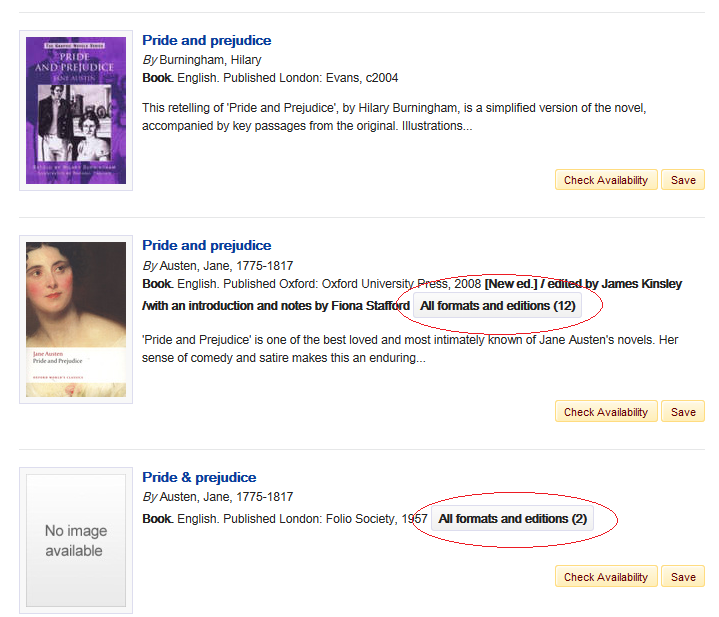
With work or expression clustering this means that all editions are brought together and represented by the latest edition. Expression level clustering separates by format, for example book and ebook, whereas work level clustering ignores format so that books and ebooks can be in the same cluster.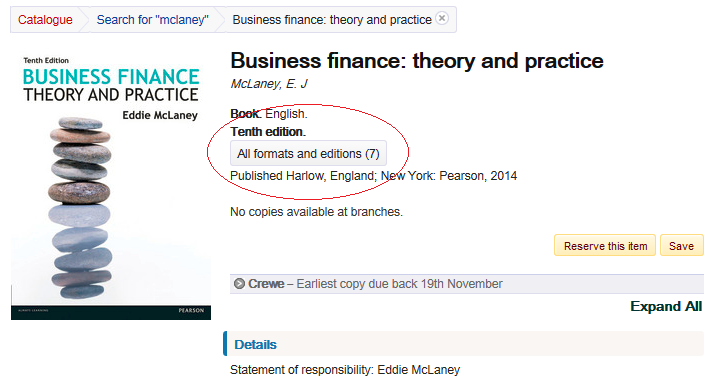
Adaptations and re-creations such as films of the book are treated as separate works, in agreement with FRBR and RDA definitions.
Manifestation level is intended to support consortial catalogues, bringing together instances of the same record from different consortium-members’ catalogues.
Clustering applies to the records posted to Prism from your LMS. We’re planning to extend this to other records that are indexed by Prism, typically those in Resource Management collections and harvested repository and archive metadata. Clustering does not apply to remote sources such as EDS or Summon.
You can see work-level clustering in action in our demonstration Prism tenancy. To get started, try the following searches and look for links to All formats and editions: english law keenan / dickens christmas carol / accounting finance / harry potter.
To get clustering in your Prism catalogue, please open a Support case and specify which level you would like to try (work or expression). Firstly, we will need to run a bulk MarcGrab to generate the clustering keys in your data. Clustering is switched off by default and we can switch between that and any level on request once the bulk MarcGrab has been done. We’ll switch it on for your Prism sandbox tenancy first to let you evaluate it; it can then be switched on for your main tenancy on request.
ePrints integration – author search
Where an ePrints repository is integrated with Prism for harvesting and indexing in Prism, author search is now supported. This works in the same way as in the local catalogue: you can simply search using key words from an author name, or use the author: search qualifer, e.g. author:mccluskey.
EDS Integration – Year Published facet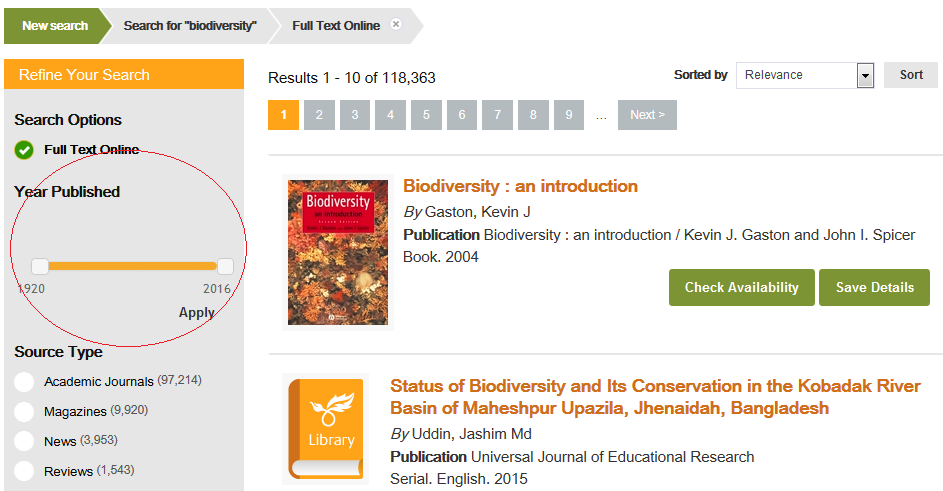
In collaboration with EBSCO, the Date Published is now available in the EDS API and Prism uses it to provide a Year Published facet on EDS search results, allowing a range to be selected as in the local catalogue.
EDS Integration – select and sort facets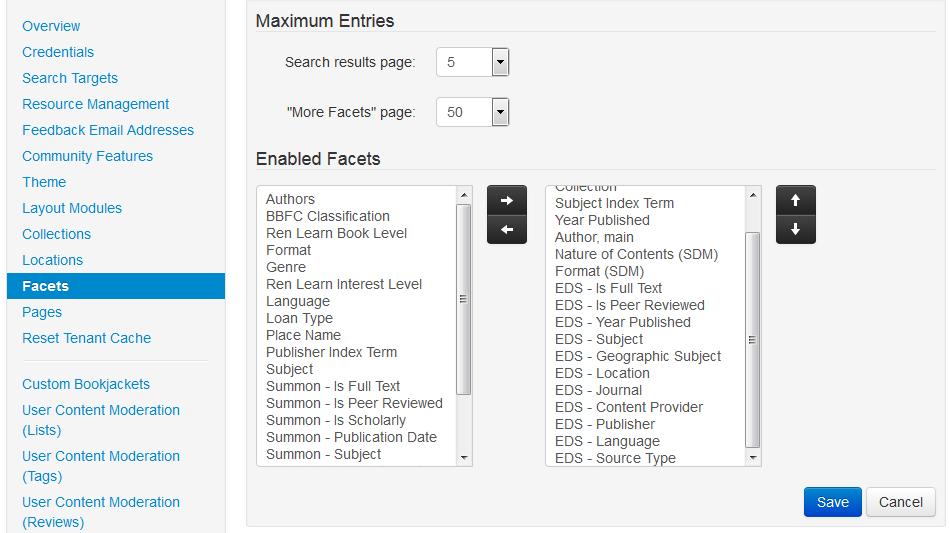
If you have EBSCO DS integrated in Prism, in the Admin Console for your Prism tenancy in the Facets area you can now select the EDS facets that you wish to display with EDS search results, and you can arrange them into the order that you want them to appear. Save your changes and run Reset Tenant Cache in the Admin Console to make your changes appear in Prism.
EDS Integration – fix hidden bib details for signed in users
This fixes a problem where, for some EDS results where details are contractually hidden from guest users, the details remained unavailable when the user signed in.
Lists moderation queue fix
This fixes a problem where lists that users had opted to make public, in a pre-moderated environment, were not displaying in the moderation queue.
Making the most of your preview
Please check the preview version as early as possible to familiarise with the new functionality and to ensure that your tenancy still behaves as expected in terms of both functionality, including extensions, and styling.
To preview this release, please precede your tenancy URL with ‘demo.’, like this: demo.capitadiscovery.co.uk/{your tenancy name}. If you have your own host name, you’ll need to use demo.capitadiscovery.co.uk instead.
Release to the live service
The release of Prism to the live service will be on Wednesday 25th November 2015.
Comments and contact
If you have any comments, questions or suggestions please get in touch. You can comment here on the Prism blog, on the Prism forum and Prism Ideas or contact your Account Manager or the Prism team directly.

November 18th, 2015 at 4:47 pm
Hi there,
We really welcome the Year published facet in EDS searching – thank you!
My only observation on the way it is implemented is that we get such a large range of years returned in the results is that I have to apply it once to a wider range and then refine it a second time. It would be useful just to be able to type in the year.
For example if I search for
nut job
using the e-journals dropdown option
the initial date range offered is 1890-2015
I want 2014, but the closest I can get to refining this initially is 2010-2015 then clicking Apply
I can then refine again to 2014
I can imagine students will find this rather laborious…
However – as I said – this is still a major improvement – thank you
Janet
November 19th, 2015 at 3:09 pm
Hi Janet, Thanks for the appreciation of EDS Year Published facet. We’ll have a look at what could be done about the high volume usability issue you’ve mentioned.
November 30th, 2015 at 11:47 am
Hi Janet,
Prism has to start with blocks of years when the date range is wide to avoid very long drop-down lists of years in the mobile view and for screen readers. EDS doesn’t return all the years in the results so Prism has to assume every year from the oldest to the newest.
December 1st, 2015 at 3:31 pm
Hi Terry,
OK – this makes sense. Thank you for following it up. If the data passed through by EDS changes, please can I ask that this is reviewed?
December 7th, 2015 at 9:32 am
Certainly. as a partner, EBSCO keeps us up to date with changes and we review rgularly.
December 7th, 2015 at 12:53 pm
Hello,
As regards the results clustering option how would this play out with linking works to Reading lists where students are recommended particular editions? – Thanks, Sally Rimmer
December 7th, 2015 at 2:17 pm
Hi Sally, Each item in a cluster has its own item detail page. Entries in reading lists for items in the catalogue should refer to the detail page for the item. So, for example, Manufacturing engineering and technology by Kalpakjian exists in four editions in your catalogue. With Work clustering, it would be represented in search results by the seventh edition and that result would link to the item detail page for the seventh edition. Both the result and the item detail page will have links to see the other editions in the cluster.
Reading List 4ME503 refers to the 6th edition and mentions that earlier editions exist. The link to view it in the catalogue takes you to the detail page for the 6th deition. With Work clustering you would then see the link to view other editions, where you would discover the seventh edition. The list owner might then update the reading list, or state why the 6th edition must be used.
December 7th, 2015 at 3:05 pm
Thanks Terry.
January 19th, 2016 at 9:59 am
As posted to the Help Desk as a Case, Clustering on Works seems to do strange things which are hard to explain, and possiblu unintelligible to your average public library user:
a) a title search which finds exact matches for many works clusters some and not others – possibly due to different author attributions and/or related ISBNSs (or not) – not alt all transparent to the user,
b) ‘Availability’ check on a cluster shows only the availability of the work displayed as default – not for all the works in the cluster – you have to open the cluster to do that. Misleading, IMO.
Please advise
Regards, JU
January 19th, 2016 at 4:27 pm
Thanks for the feedback, John. Work clustering is based on title and author information. It has to create valid clusters but avoid creating invalid ones, and we’ve tried to make it err towards the latter. Both software logic and data can give rise to imperfect results. We’re happy to consider ways to improve it. We’ll see what we can learn from your examples in the case.
With clustering, results entries are still individual items (i.e. editions or versions). For a cluster you see the most recent item matching your query, in the results – it includes publication and edition information. So selecting that item gives you the Item Detail page for that item, with its availability information, just as without clustering. The clustering link allows you to visit the other members of the cluster and view their availabilities.
January 26th, 2016 at 2:24 pm
Then I’ll have Capita turn this off in Sandbox and wait until the issues above are addressed. I think this will cause more queries from users we shouldn’t have to field.
Regards, JU
February 1st, 2016 at 1:00 pm
Hi Terry
We like the results clustering (we have work clustering switched on) but we’ve had feedback from library staff at 3 sites now who say their users are missing the button and therefore missing resources. Can we make it stand out more on our tenancy? A different colour maybe?
Claire
February 3rd, 2016 at 10:18 am
Hi Claire, Good to hear that clustering is useful. We’re opening a Support case about the styling of the clustering link and will be in touch with you directly through that channel.
February 4th, 2016 at 1:20 pm
Great, many thanks Terry
March 8th, 2016 at 9:41 am
Hi Terry
Another bit of feedback we’ve had is that titles with several editions where one used ‘and’ in the title and others use ‘&’ are not clustered. We wondered whether clustering the same title regardless of whether &/and are used was possible
Claire
March 8th, 2016 at 2:17 pm
Hi Claire, That’s a good point. We’ve aded it to our internal list. It would be good if you could send me links to one or two examples.
April 5th, 2016 at 2:54 pm
Hi Terry, re: and vs. & – Strategic management: concepts & cases and Strategic management: concepts and cases create two different clusters on our tenancy.
April 5th, 2016 at 4:12 pm
Hi Meghan, Thanks for the example.
February 21st, 2017 at 10:28 am
Hi,
We have had results clustering enabled and are experiencing instances where not all correct candidates are clustered (title change etc) and we can understand and live with this. However, another consequence has been clusters that merely duplicate a bib record. See:
https://capitadiscovery.co.uk/derby-ac/items?query=work%3Ab8c0e340-31cc-546b-8751-21c645493f86&facet%5Bexpand%5D=work%3Ab8c0e340-31cc-546b-8751-21c645493f86
I have logged a support case but am interested on your opinion on why this might be happening. Thanks, Sally
February 22nd, 2017 at 3:02 pm
Hi Sally, This appears to be a bug involving different versions of the same record stored in Prism, where all are counted for clustering when it should only recognise the latest.
I have raised a bug report for it and informed Support via a note on your case.
February 24th, 2017 at 11:57 am
Many thanks Terry.