Several weeks ago we had a development update webinar where we explained the Semantic Data Model theme from the roadmap in more detail. We’d had conversations with several people one-to-one about this theme as questions were raised and the webinar was a great chance to discuss this important work more widely. I’d like to thank those of you who followed up with us after the webinar with support, feedback and valuable suggestions. For those who couldn’t make it, for those who wanted information to pass on to colleagues and for those who wanted a point of reference to refer back to, here it is.
As many of you know, Prism 3 doesn’t use MARC as its underlying data format. While MARC is a very useful and valuable model Prism 3 requires something much more flexible and extensible. Of course, you have a significant investment in your MARC data, years of cataloguing – keeping the human investment made in the cataloguing, while moving it to a technical form that provides more flexibility will let Prism 3 do more with the data you’ve invested in. The Semantic Data Model theme of work is about improving three main areas.
Firstly, we need more from the original MARC record for indexing and display. Secondly, Prism 3 has further search and browse features on the roadmap. Thirdly we want to provide a comprehensive Application Programming Interface, API.
What this means in Prism 3 is that we will be able to provide a much more browsable catalogue with pages for every author, for subjects, for each collection and location. This gives us the places to extend Prism and it will give your users the links to really explore what you have.
These pages will be linked, back and forth, providing a browsable interface not only for your users but also for search engines. Allowing search engines to crawl your catalogue, indexing it and making your catalogue much more visible in search results.
The API will allow you to get at your data in more ways and to re-use your data in other places. Fancy embedding search results in a Facebook app? Or tracking new stock in your RSS feed reader? The API will allow you to make use of your data in these kinds of ways. The format of the data will be in a variety of flavours, including XML and JSON, to support the way web developers work today.
The API will also allow richer extensions to be built for Prism 3 itself, allowing you, the community of users, to develop and share additional features using JavaScript frameworks like Juice. Your data will be easier to get at, enhance and re-use.
The data model we are building on is also extensible, meaning we can add to it as new requirements come to light. This will allow us to build more into the data model in future, things like FRBR style groupings. It is also the same style of linked data as is being used by the BBC and Library of Congress and being explored the British Library. This means that further down the road there is the opportunity to link books in your catalogue with BBC programmes that they relate to, or to historical information at the British Library or Library of Congress.
The Semantic Data Model work in Prism 3 isn’t inventing something entirely new though. It builds on work done over many years in MARC21, both bibliographic data and authority data, as well as standards such as Dublin Core, RDA, FRBR and RDF. And, looking further back, the card indexes of Charles Ami Cutter. The model will really allow the investment in cataloguing and catalogue data that you have made to shine in Prism 3, helping your users to find, and get at, what they need more easily.
So, the bulk of the work we’re doing is about going from a MARC record, which has simple names in it, to a data model that has rich relationships in it. That is where the Semantic Data Model fits in. So, it’s a data model for Prism 3, but where does the word ‘Semantic’ come from?
The technology behind what we’re doing comes from the next generation of the web, a web of data. This web is already being built and is an enhancement to the web today, not a replacement for it. This web of data, or Semantic Web, is already being supported by UK and US Government initiatives and by major media organisations such as the BBC and New York Times. The Semantic Data Model will allow Prism 3 not only to provide new and richer features for discovery, but also prepares the ground for libraries to participate in the web of data.
For those who attended the webinar and asked for the slides, they’re available here.
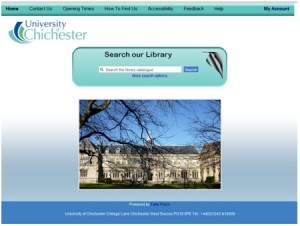 The University of Chichester are now live with their new catalogue, parallel running both Prism 2 and Prism 3 for a few weeks before moving to Prism 3 as the default catalogue. This gives staff and students alike a great opportunity to try out the new OPAC as the project team in charge of the implementation at the University were keen to allow staff and students to migrate to the new service naturally.
The University of Chichester are now live with their new catalogue, parallel running both Prism 2 and Prism 3 for a few weeks before moving to Prism 3 as the default catalogue. This gives staff and students alike a great opportunity to try out the new OPAC as the project team in charge of the implementation at the University were keen to allow staff and students to migrate to the new service naturally.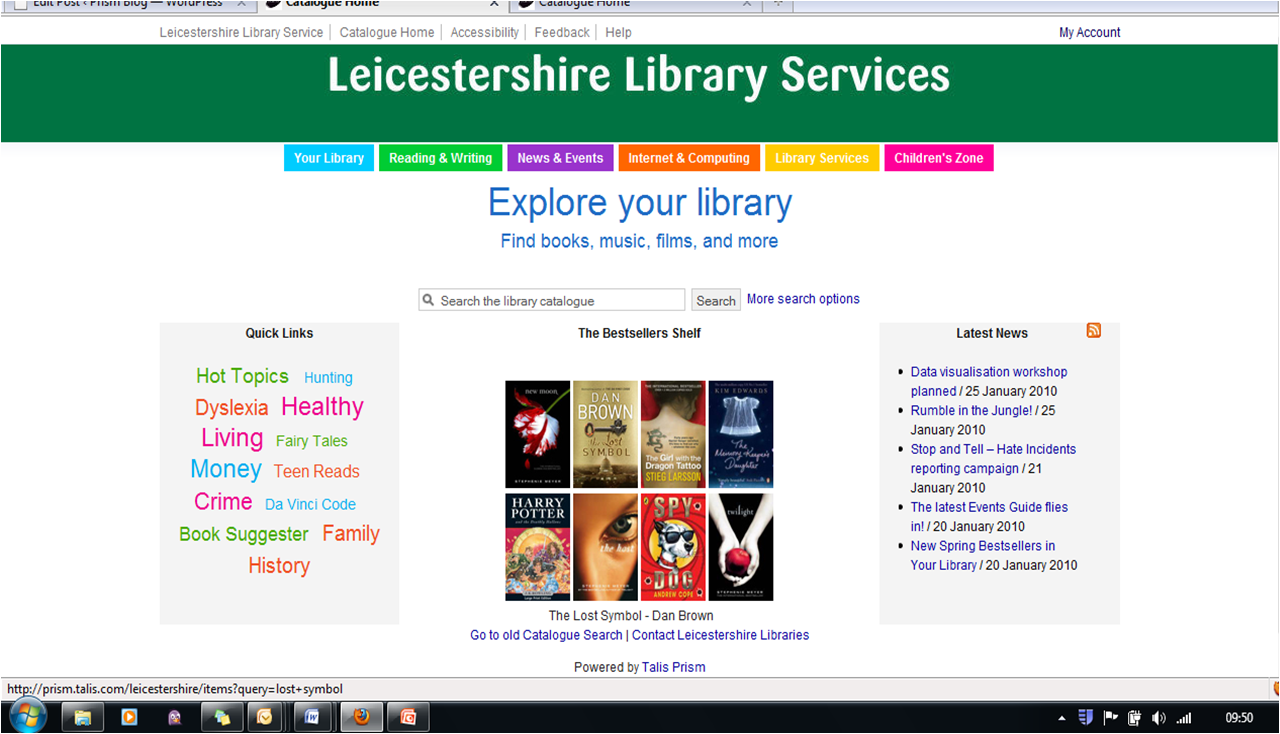



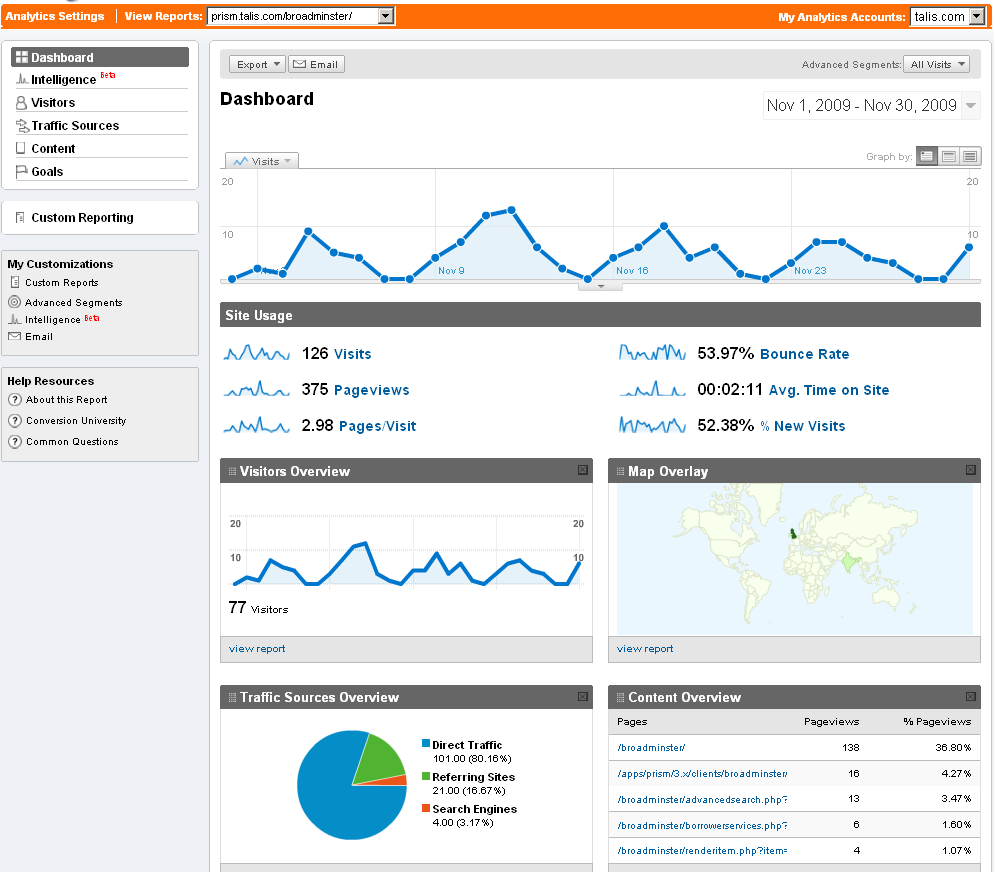
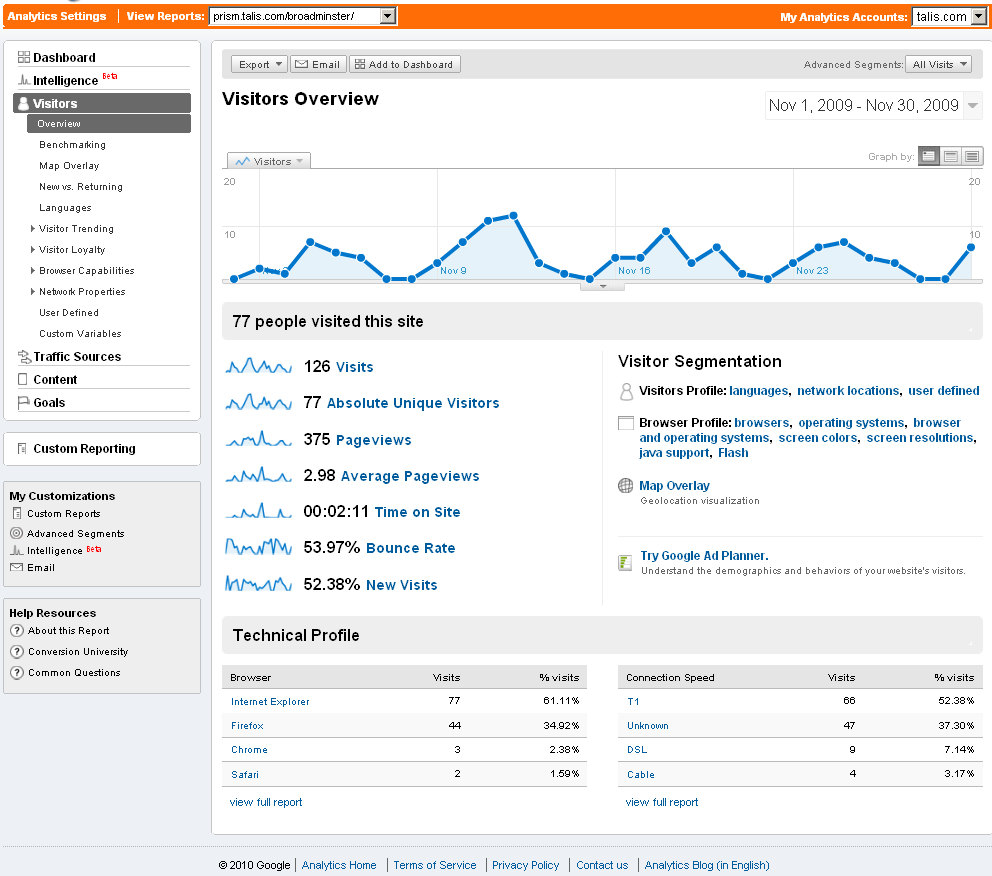

Recent Comments